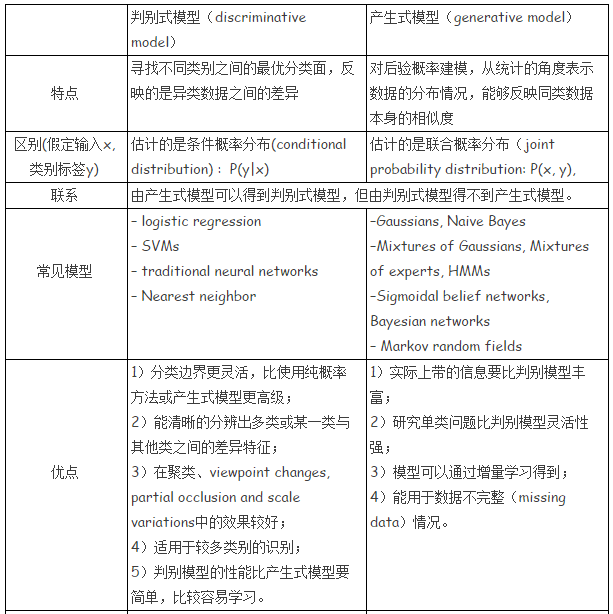
判别式模型和生成式模型
区别
对分类任务来说,若目标是最小化分类错误率(对应0/1损失),得到条件风险和最小化分类错误率的最优分类器分别为:
$$R(c|\mathbf{x}) = 1- P(c|\mathbf{x})$$
$$h*(x) = argmax_{c\in \mathcal{Y}} P(c|\mathbf{x})$$
即对每个样本x,选择能使后验概率P(c|x)最大的类别标识。
“判别式模型”
直接建模估计条件概率分布P(c|x)(事实上很多机器学习技术无需准确估计出后验概率就能准确进行分类).在建模的过程中不需要关注联合概率分布。只关心如何优化p(c|x)使得数据可分。通常,判别式模型在分类任务中的表现要好于生成式模型。但判别模型建模过程中通常为有监督的,而且难以被扩展成无监督的。
常见的判别式模型有:
- 逻辑回归,线性回归,线性判别分析,神经网络,支持向量机,Boosting,条件随机场
“产生式模型”
对联合概率分布P(x,c)建模,再获得P(c|x).该模型对观察序列的联合概率分布p(x,c)建模,在获取联合概率分布之后,可以通过贝叶斯公式得到条件概率分布。生成式模型所带的信息要比判别式模型更丰富。除此之外,生成式模型较为容易的实现增量学习。
常见的生成模型有:
- 朴素贝叶斯,隐马尔科夫模型,LDA,受限玻尔兹曼机,高斯混合模型和其他混合模型
由上可知,判别模型与生成模型的最重要的不同是,训练时的目标不同,判别模型主要优化条件概率分布,使得x,y更加对应,在分类中就是更可分。而生成模型主要是优化训练数据的联合分布概率。而同时,生成模型可以通过贝叶斯得到判别模型,但判别模型无法得到生成模型。
图示区别

来自李航的《统计学习方法》
样本x,类别y
生成方法由数据学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型。P(Y|X) = P(X,Y)/P(X)
这样的方法称为生成方法,是因为模型表示了给定输出X产生输出Y的生成关系。
判别方法由数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测的模式,即判别模型。判别方法关心的是对给定的输入X,应该预测什么样的输出Y。
生成方法的特点:
- 生成方法可以还原出联合概率分布P(X,Y),而判别方法不能;
- 生成方法学习收敛速度更快,即当样本容量增加时候,学到的模型更快收敛于真实模型
- 当存在隐变量时,仍可以用生成方法学习,此时判别方法就不能用
判别方法的特点:
- 判别方法直接学习的是条件概率或者决策函数,直接面对预测,往往学习的准确率更高。
- 由于直接学习P(Y|X)或f(X),可以对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习问题
