机器学习(周志华)- 第11章特征选择与稀疏学习笔记
维度缩减的原因
- 维数灾难。较少复杂度
- 除去不相关特征降低学习难度
因此,需要去掉冗余属性和不相关属性。
维度约减的两个主要过程
子集搜索(搜索策略)
一般采用贪心的方法,否则想获取全局最优必须穷举所有可能组合。
往目前的子集中按一定顺序去增加、减少属性,因为是一个一个地加,故是局部最优的。有前向搜索、后向搜索和双向搜索等。1) 朴素序列特征选择:对属性进行评分然后按分值大小排列,选取分数最高的M个属性。基本不能用,因为没有考虑到属性之间的相互依赖。
2) 顺序向前选择(SFS):以一个空集开始,然后向空集中增加一个属性,该属性在给定某个分类器时要有最大识别率。然后在剩余的属性集中依次取出一个属性,使组合起来的识别率最大。当识别率不在增大或者减小时停止加入属性。
当最终最优子集特征数目比较小时用这个方法最好。然而加入属性后就不能再取出。3) 顺序向后选择(SBS):选择所有属性放入集合,第一次拿出一个识别率最低的属性,然后依次拿出属性直到拿出一个属性后该属性集合的性能不升高反而下降。
当最终最优子集特征数目比较大时用此方法最好。但是一旦拿出一个属性就不能放回去。Both SFS and SBS algorithms suffer from the so called nesting problem: once a feature is added or removed, this action can never be reversed
4) 双向搜索(BDS):从空集开始使用SFS,从全集开始使用SBS,每一次确保SFS选择的属性SBS不能删除,SBS删除的属性SFS不能选择。
For example, before SFS attempts to add a new feature, it checks if it has been removed by SBS; and, if it has, attempts to add the second best feature, and so on. SBS operates in a similar fashion.
5) 序列漂浮向前选择(SFFS):从空集开始,每次用SFS增加一个属性的同时用SBS检查该集合内是否有可以删除的属性,循环该过程,直到该属性集合的识别率下降停止。
子集评价(目标函数)
- 评价指标:信息熵增益、不合度量、相关系数等可以判断两个划分差异的都可以
- 评价测策略:
a) Filters:目标函数评价属性用属性所含的信息量,而和要用的预测算法无关,是一种无指导的选择方法。它主要解决特征之间的相关性。相关性是由数据集本身的特性决定的。侧重于相关性。无监督
b) Wrappers:目标函数本身就是一个学习器,用预测精度来评估。它主要通过统计抽样和交叉验证的精度来评估特征子集,计算成本较高。有监督
过滤式选择
过滤式方法先对数据集进行特征选择,然后再训练学习器,特征过程选择与后继学习器无关。这相当于先用特征选择对初始特征进行“过滤”,再用过滤后的特征来训练模型。
Relief是一种著名的过滤式特征选择的方法,该方法设计了一个“相关统计量”来度量特征的重要性。该统计量是一个向量,其每个分量分别对应一个初始特征,而特征子集的重要性则是由每个特征对应的相关统计量分量所对应的计量分量之和来决定。于是最终只需要找出相关统计量分量对应的特征大于阈值的即可。
相关统计度量采用“猜对近邻”和“猜错近邻”结合。
包裹式选择
与过滤式特征不考虑后继学习器不同,包裹式特征选择直接把最终将要使用的学习器的性能作为特征子集的评价准则。换言之,包裹式特征选择的目的就是为给定学习器选择有利于其性能、“量身定做”的特征子集。
一般包裹式的最终学习器性能比过滤式好,但是计算开销大得多。
LVW是一个典型的包裹式特征选择方法,它在拉斯维加斯方法框架下使用随机策略来进行子集搜索,并以最终分类器的误差作为特征子集评价准则。
嵌入式选择与L1正则化
与前面两者不同,嵌入式选择时将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动的进行特征选择。
给定数据集,考虑最简单的线性回归模型,以平方误差为损失函数,则优化目标是:
$$min_w \sum_{i=1}^m (y_i - w^T x_i)^2 \quad (1)$$
当样本特征很多而样本数很少的时候,(1)会陷入过拟合。为了缓解过拟合,我们引入正则化项,若使用L2范数正则化,则有:
$$min_w \sum_{i=1}^m (y_i - w^T x_i)^2+ λ||w||_2^2 \quad (2)$$
其中正则化参数λ>0,(2)称为岭回归。
那么能将L2范数换为Lp范数吗?答案是可以。例如L1范数
$$min_w \sum_{i=1}^m (y_i - w^T x_i)^2+λ||w||_1 \quad (3)$$
(3)称作LASSO(最小绝对化收缩因子)。
L1范数和L2范数正则化都有助于降低过拟合的风险,但是L1还会带来一个额外好处:L1比L2更容易获得“稀疏解”,即求得的w会有更少的非零分量。
如图: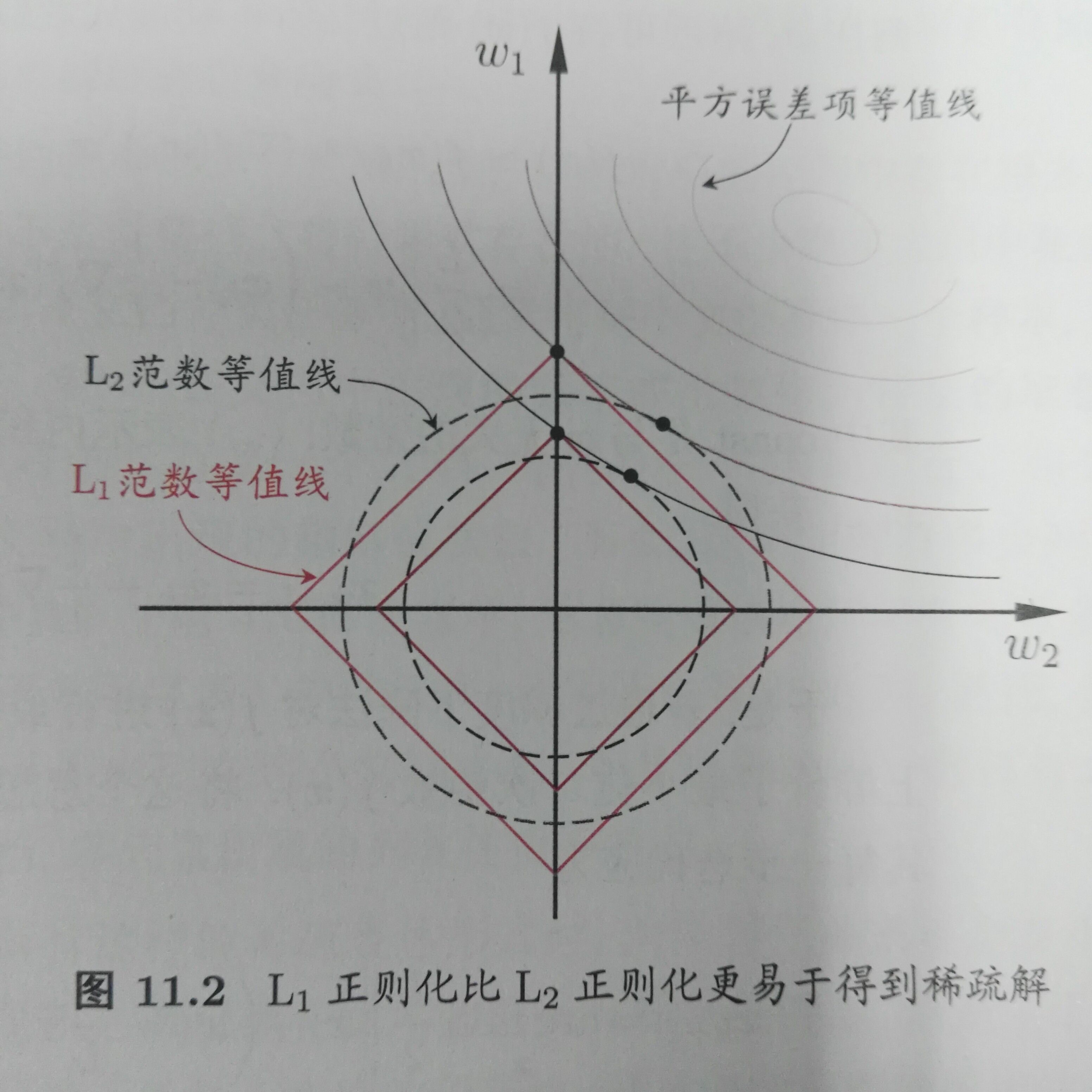
采用L1范数的平方误差等值线与正则化项的等值线常出现在坐标轴,而L2常出现在象限。L1比L2更容易得到稀疏解。
注意到w取得稀疏解意味着初始的d个特征中仅有对应着w的非零向量的特征才会出现在最终的模型中。于是,求解L1范数正则化的结果得到了仅仅采用一部分初始特征的模型,换言之,L1正则化的学习方法就是一种嵌入式的特征选择方法,其特征选择过程与学习器训练过程融为一体,同时完成。
L1正则化问题的求解可以用近端梯度下降(Proximal Grandient Descent,PGD)。
稀疏表示与字典学习
当赝本具有一定的稀疏表达形式的时候,问题容易变得线性可分。因此我们考虑为普通稠密表达的样本找到合适的字典,将样本转换为合适的稀疏表达式,从而使学习任务得以简化,模型复杂度得以降低,通常称为“字典学习”,亦称“稀疏编码”。
字典学习更侧重于学得字典的过程而稀疏编码侧重于样本进行稀疏表达的过程。
