Word2vec解析
参考资料:
- http://www.cnblogs.com/peghoty/p/3857839.html
- http://licstar.net/archives/328
- http://techblog.youdao.com/?p=915#LinkTarget_699
什么是word2cex
word2vec 是 Google在2013年中开源的一款将词表征为实数值向量高效工具 ,采用的 模型 有 CBOW(Continuous ontinuous Bag -Of-Words ords ,即连续的词袋模型 )和 Skip-Gram两种。 word2vec 代码链接为: https://code.google.com/p/word2vec/。
word2vec 一般被外界认为是个DeepLearning(深度学习)的模型,究其原(深度学习)的模型,可能和word2vec的作者 Tomas Mikolov的 Deep Learning Deep Learning Deep LearningDeep背景以及word2vec 是一种神经网络模型相关,但我们谨慎 认为该模型层次较浅,严格来说还不能算是深层模型。当然如果 word2vec上层 再套一上层应用相关的输出层,比如Softmax,此时更像是一个深层模型。
word2vec 通过训练,可以把对文本内容的处理简化为通过训练,可以把对文本内容的处理简化为 K维向量空间中的运算,而向量空间上的相似度可以用来表示文本语义。因此,word2vec输出的词向量可以被 用来做很多 NLP 相关的工作,比如聚类、找同义词性分析等 。而word2vec被人广为传颂的地方是其向量 的加法组合 运算 (Additive Compositionality ),官网上的例子是: vector(‘Paris’) - vector(‘France’) +vector(‘Italy’) ≈vector(‘Rome’),vector(‘king’) - vector(‘man’) + vector(woman’) ≈ vector(‘queen’) 。但我们认为这个多少有点被过度炒作了, 很多其他降维或主题模型在一定程度也能达到类似效果,而word2vec 也只是少量的例子完美符合这种加减法操作,并不是所有的case都满足。 word2vec 大受欢迎的另一个原因是其高效性。
如果换个思路,把词当做feature,那么 word2vec 就可以把 feature映射到 K维向量空间,应该可以为现有模型提供更多的有用信息。
词向量是什么
自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化。
NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
举个栗子,
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
每个词都是茫茫 0 海中的一个 1。
这种 One-hot Representation 如果采用稀疏方式存储,会是非常的简洁:也就是给每个词分配一个数字 ID。比如刚才的例子中,话筒记为 3,麦克记为 8(假设从 0 开始记)。如果要编程实现的话,用 Hash 表给每个词分配一个编号就可以了。这么简洁的表示方法配合上最大熵、SVM、CRF 等等算法已经很好地完成了 NLP 领域的各种主流任务。
当然这种表示方法也存在一个重要的问题就是“词汇鸿沟”现象:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系,哪怕是话筒和麦克这样的同义词也不能幸免于难。
Deep Learning 中一般用到的词向量并不是刚才提到的用 One-hot Representation 表示的那种很长很长的词向量,而是用 Distributed Representation(不知道这个应该怎么翻译,因为还存在一种叫“Distributional Representation”的表示方法,又是另一个不同的概念)表示的一种低维实数向量。这种向量一般长成这个样子:[0.792, −0.177, −0.107, 0.109, −0.542, …]。维度以 50 维和 100 维比较常见。这种向量的表示不是唯一的,后文会提到目前计算出这种向量的主流方法。
(个人认为)Distributed representation 最大的贡献就是让相关或者相似的词,在距离上更接近了。向量的距离可以用最传统的欧氏距离来衡量,也可以用 cos 夹角来衡量。用这种方式表示的向量,“麦克”和“话筒”的距离会远远小于“麦克”和“天气”。可能理想情况下“麦克”和“话筒”的表示应该是完全一样的,但是由于有些人会把英文名“迈克”也写成“麦克”,导致“麦克”一词带上了一些人名的语义,因此不会和“话筒”完全一致。
词向量的来历
Distributed representation 最早是 Hinton 在 1986 年的论文《Learning distributed representations of concepts》中提出的。Distributed representation 用来表示词,通常被称为“Word Representation”或“Word Embedding”,中文俗称“词向量”(词嵌入?)。
如果用传统的稀疏表示法表示词,在解决某些任务的时候(比如构建语言模型)会造成维数灾难[Bengio 2003]。使用低维的词向量就没这样的问题。同时从实践上看,高维的特征如果要套用 Deep Learning,其复杂度几乎是难以接受的,因此低维的词向量在这里也饱受追捧。
同时如上一节提到的,相似词的词向量距离相近,这就让基于词向量设计的一些模型自带平滑功能,让模型看起来非常的漂亮。
词向量的训练
要介绍词向量是怎么训练得到的,就不得不提到语言模型。到目前为止我了解到的所有训练方法都是在训练语言模型的同时,顺便得到词向量的。
这也比较容易理解,要从一段无标注的自然文本中学习出一些东西,无非就是统计出词频、词的共现、词的搭配之类的信息。而要从自然文本中统计并建立一个语言模型,无疑是要求最为精确的一个任务(也不排除以后有人创造出更好更有用的方法)。既然构建语言模型这一任务要求这么高,其中必然也需要对语言进行更精细的统计和分析,同时也会需要更好的模型,更大的数据来支撑。目前最好的词向量都来自于此,也就不难理解了。
这里介绍的工作均为从大量未标注的普通文本数据中无监督地学习出词向量(语言模型本来就是基于这个想法而来的),可以猜测,如果用上了有标注的语料,训练词向量的方法肯定会更多。不过视目前的语料规模,还是使用未标注语料的方法靠谱一些。
词向量的训练最经典的有 3 个工作,C&W 2008、M&H 2008、Mikolov 2010。当然在说这些工作之前,不得不介绍一下这一系列中 Bengio 的经典之作。
统计语言模型
语言模型其实就是看一句话是不是正常人说出来的。这玩意很有用,比如机器翻译、语音识别得到若干候选之后,可以利用语言模型挑一个尽量靠谱的结果。在 NLP 的其它任务里也都能用到。
语言模型形式化的描述就是给定一个字符串,看它是自然语言的概率 $P(w_1, w_2, …, w_t)$。w1到 wt 依次表示这句话中的各个词。有个很简单的推论是:
$$P(w_1, w_2, …, w_t) = P(w_1) \times P(w_2 | w_1) \times P(w_3 | w_1, w_2) \times … \times P(w_t | w_1, w_2, …, w_{t-1})$$
常用的语言模型都是在近似地求$P(w_t | w_1, w_2, …, w_{t-1})$,比如 n-gram 模型就是用$P(w_t | w_{t-n+1}, …, w_{t-1})$近似表示前者。
其中的条件概率可以看做语言模型的参数。但是穷举的话这个参数很多。
这些参数可以通过n-gram模型、决策树、最大熵马尔科夫模型等。
n-gram 模型
做了一个n-1阶的Markov假设,认为一个词出现的频率就治愈前面的n-1个词相关。
在计算复杂度方面,模型参数量级是N的指数函数(O(N^n))N是词典大小。n不能取太大,一般取2或者3.
在模型效果方面,n越大效果也好,但是越大,提升幅度约不明显。
n-gram语言模型存在一些问题;
- n-gram语言模型无法建更远的关系,语料不足使得训练高阶模型无法训练高阶语言模型 。大部分研究或工作都是使用Trigram ,就算使用高阶的模型,其统计到的概率可信度就大打折扣,还有一些比较小问题采用 Bigram。
- 这种模型无法建出词之间的相似度,有时候两个具某性如果一个词经常出现在某段之后,那么也许另这面的概率 如果一个词经常出现在某段之后,那么也许另这面的概率 也比较大 。比如“白色的汽车”经常出现,那完全可以认为轿也能经常出现。
- 训练语料里面有些n元组没有出现过,其对应的条件概率就是 0,导致计 算一整句话的概率为 0,解决办法:
1)平滑法。把么个n’元组出现次数加1,那么原来出现k次的某个n元组就会记为k+1次,原来出现0次的n元组就会记为出现1次。这种也成为Laplace平滑。当然还有很多更复杂的其他平滑方法,其本质都是将模型变为贝叶斯模型,通过引入先验分布打破一统天下的局面。而引入的先验方法的不同也就产生了很多不同的平滑方法。
2)回退法。有点像决策树中的后剪枝方法 ,即如果 n元的概率不到,那就 往上回退一步,用 n-1元的概率乘上一个权重来模拟。
3)n-pos模型。严格来说 n-pos 只是 n-gram 的一种衍生模型。 n-gram 模型假定第 t个词出现概率条件依赖它前N-1个词,而现实中很多词出现的概率是条件依赖于它前面的语法功能的。n-pos 模型就是基于这种假设的模型,它将词按照其语法功能进行分类,由这些词决定下一个出现的概率。样称为 词性 (PartPart -of -Speech Speech Speech,简称为 ,简称为 POS )。n-pos 模型中的每个词条件概率表示为:
$$p(s) = p(w_1^T)=p(w_1,w_2,…,w_T)=\prod_{t=1}^T p(w_t|c(w_{t-n+1}), c(w_{t-n+2}),…,c(w_{t-1}))$$
c为类别隐射函数,把T个词映射到k个类别。是加上采用了一种聚类的思想,同时还较少了语义有意义的类别。当然还有很多变种。
基于决策树的语言模型
上面提到的下文无关语言模型 、n-gram语言模型 语言模型 、n-pos 语言模型 等,
都可以统计决策树的形式表示出来。 而统计决策树中每个结点的规则是一个上下文相关的问题 。这些问题可以是“前一个词时 这些问题可以是“前一个词时 w吗?”“前一个词属于类 吗?”“前一个词属于类别ci吗?”。 吗?”。 当然基于决策树的语言模型还可以更灵活一 些,可以是“前一个词是动词吗?”,“后面有介词吗?”之类的复杂语义问题。
基于决策树的语言模型优点是:分布数不是预先固定好的,而根据训练料库中的实际情况确定 ,更为灵活。缺点是:构造统计决策树的问题很困难,且时空开销很大。
最大熵模型
基本思想是:对一个随机事件的概率分布进行预测的时候,在满足全部已知条件下对未知的情况不做任何主观假设。从信息论的角度来说就是:在只掌握关于未知分布的部分知识时,应当选取符合这些知识但又能使熵最大的概率分布。
$$p(w|Context) = \frac{e\sum_i \lambda_i f_i (context,w )}{Z(Context)}$$
λ是参数,Z是归一化因子,因为采用的是Softmax 形式,因此最大熵模型有时候也称作指数模型。
自适应语言模型
前面的模型概率分布都是预先从训练语料库中估算好,属于静态语言模型。 而自适应语言模型类似是 Online Learning 的过程,即根据少量新数动态调整模 的过程,即根据少量新数动态调整模 型,属于动态模型。 在自然语言中,经常出现这样象:某些文本通很少出现的词,在某一局部文本中突然大量地出现。能够根据情况动态地调整语言模型中的概率分布数据成为动态、自适应或者基于缓存的语言模型。 通常的做法是将静态模型与动过参数融合到一起,这种混合模型可以有效地避免数据稀疏的问题 。
Bengio 的经典之作–神经概率语言模型
训练语言模型的最经典之作,要数 Bengio 等人在 2001 年发表在 NIPS 上的文章《A Neural Probabilistic Language Model》。当然现在看的话,肯定是要看他在 2003 年投到 JMLR 上的同名论文了。
Bengio 用了一个三层的神经网络来构建语言模型,同样也是 n-gram 模型。如图1。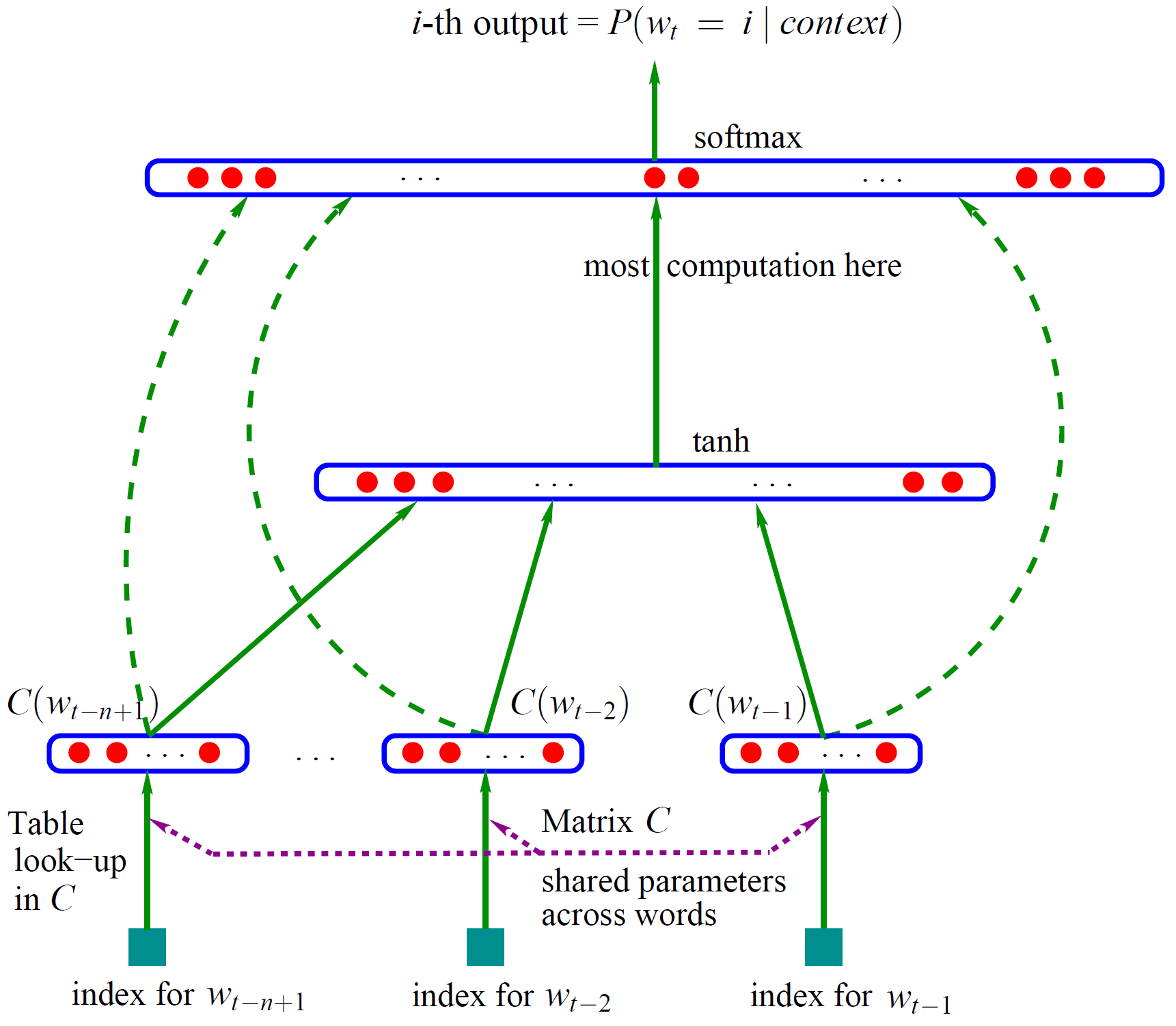
(图1)
图中最下方的wt−n+1,…,wt−2,wt−1就是前n−1 个词。现在需要根据这已知的n−1 个词预测下一个词wt。C(w)表示词w所对应的词向量,整个模型中使用的是一套唯一的词向量,存在矩阵 C(一个 |V|×m| 的矩阵)中。其中|V| 表示词表的大小(语料中的总词数),m 表示词向量的维度。w 到 C(w)的转化就是从矩阵中取出一行。
网络的第一层(输入层)是将$C(w_{t-n+1}), …, C(w_{t-2}), C(w_{t-1})$这n−1 个向量首尾相接拼起来,形成一个(n−1)m 维的向量,下面记为x。
网络的第二层(隐藏层)就如同普通的神经网络,直接使用 d+Hx计算得到。d 是一个偏置项。在此之后,使用tanh作为激活函数。
网络的第三层(输出层)一共有|V|个节点,每个节点yi表示下一个词为i的未归一化 log概率。最后使用softmax激活函数将输出值 y 归一化成概率。最终,y的计算公式为:
$$y = b + Wx + U\tanh(d+Hx)$$
式子中的U(一个|V|×h的矩阵)是隐藏层到输出层的参数,整个模型的多数计算集中在 U 和隐藏层的矩阵乘法中。后续很多工作,都有对这一环节的简化,提升计算的速度。
式子中还有一个矩阵 W(|V|×(n−1)m),这个矩阵包含了从输入层到输出层的直连边。直连边就是从输入层直接到输出层的一个线性变换,好像也是神经网络中的一种常用技巧(没有仔细考察过)。如果不需要直连边的话,将 W 置为 0 就可以了。在最后的实验中,Bengio 发现直连边虽然不能提升模型效果,但是可以少一半的迭代次数。同时他也猜想如果没有直连边,可能可以生成更好的词向量。
实际上可以看做多了一层的神经网络,如下图: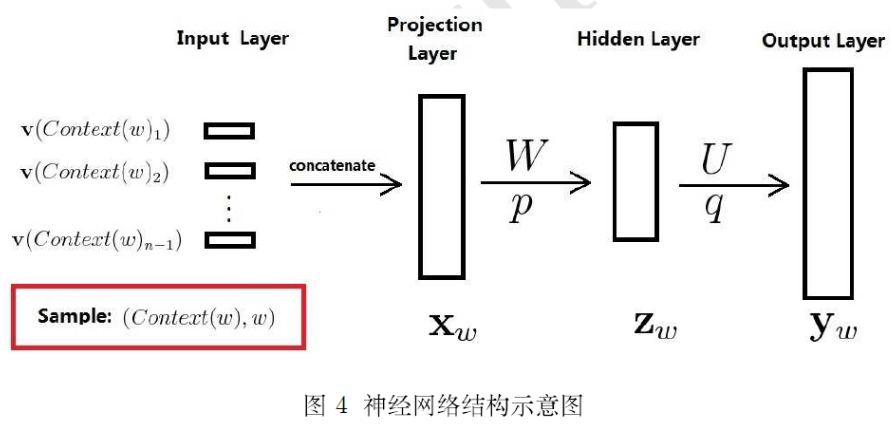
现在万事俱备,用随机梯度下降法把这个模型优化出来就可以了。需要注意的是,一般神经网络的输入层只是一个输入值,而在这里,输入层 x 也是参数(存在 CC 中),也是需要优化的。优化结束之后,词向量有了,语言模型也有了。
这样得到的语言模型自带平滑,无需传统n-gram模型中那些复杂的平滑算法。Bengio 在 APNews 数据集上做的对比实验也表明他的模型效果比精心设计平滑算法的普通 n-gram 算法要好 10% 到 20%。
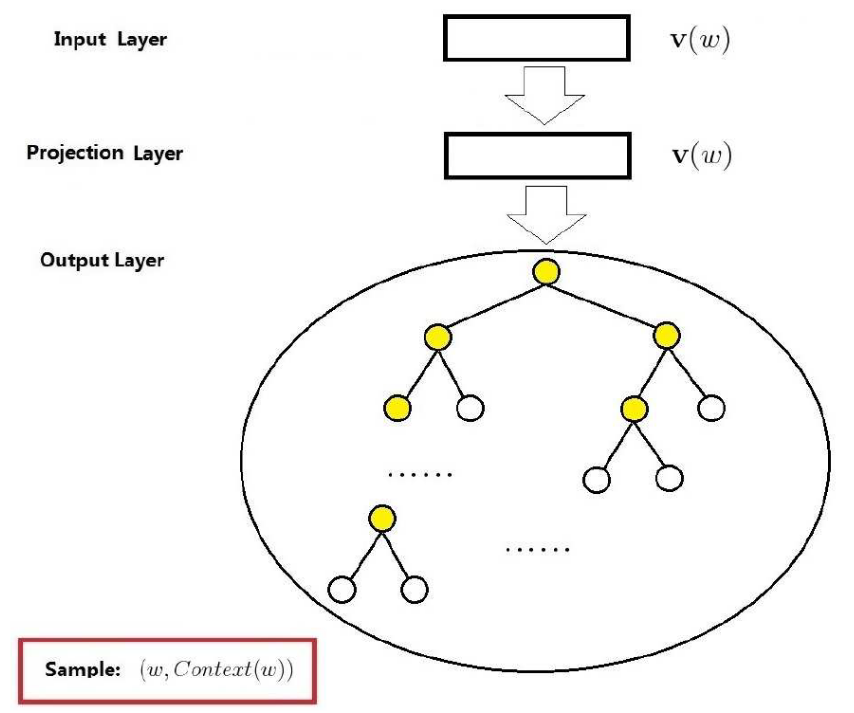
基于Hierarchical Softmax的模型
word2vec里面用到的两个重要模型:CBOW(continuous Bag-of-Words Model)和Skip-Gram模型(Continuous Skip-gram Model)。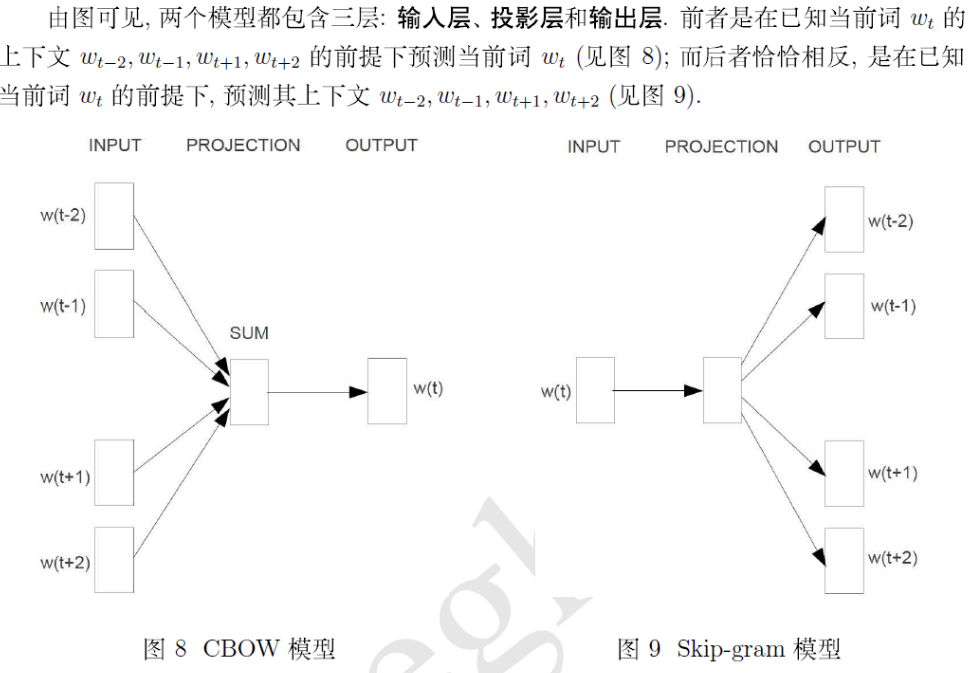

CBOW模型
包括三层,输入层、投影层和输出层。
- 输入层,包括Context(w)中2c个词的词向量v(Context(w)_1),…v(Context(w)_2c)
- 投影层,将2c个向量做累加求和。
- 输出层,对应一颗二叉树,它是以语料中出现过的词当做叶子节点,以各词在语料中出现的次数当权值构造出来的Huffman树。叶子节点共N个,对应词典数,非叶子节点N-1个。
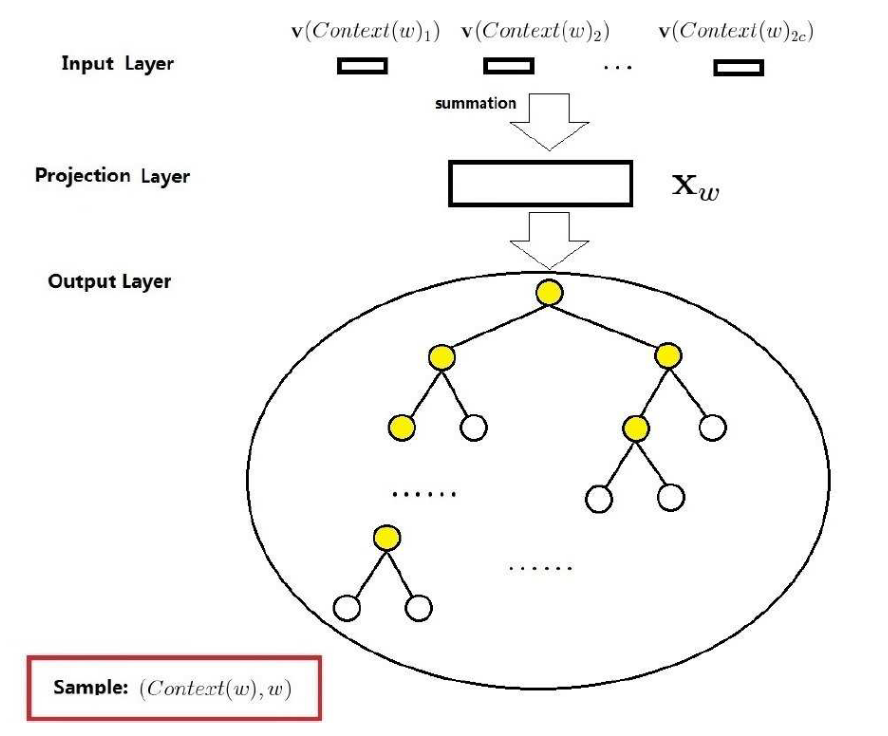

梯度计算

简单的例子如下: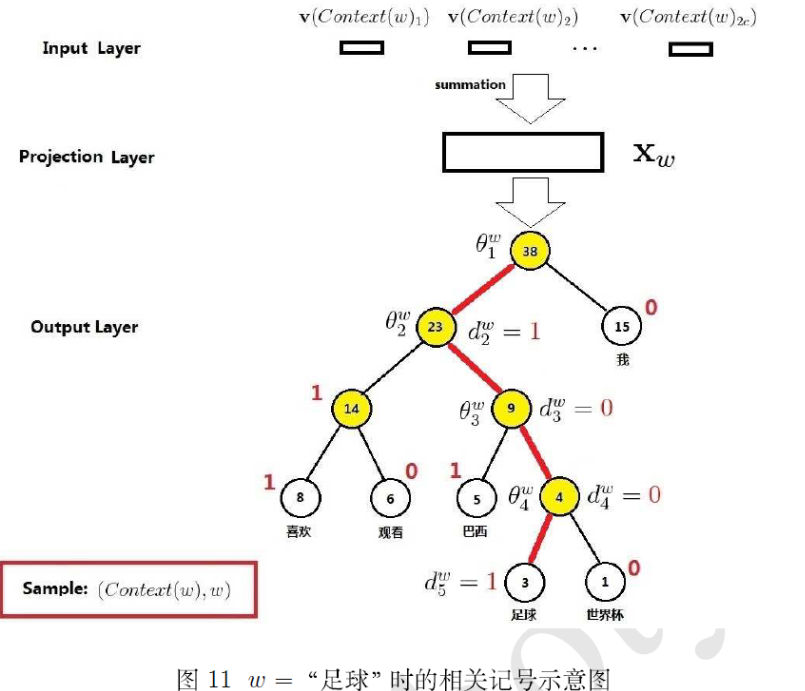






Skip-gram模型
同样包含三层
- 输入层:只含有当前样本的中心词w的词向量v(w)
- 投影层:是恒等投影,其实是多余的,只是为了和CBOW比较。
- 输出层:输出层也是Huffman树
梯度计算




基于Negative Sampling的模型
是Noise Contrastive Estimation的一个简化版本,目的是用来提高训练速度并改善所得词向量的质量。与Hierarchical Softmax不同,NEG不再使用复杂的Huffman树,而是利用(相对简单的)随机负采样,大幅提高性能,可以看做Hierarchical的一种替代。
CBOW模型






skip-gram模型
负采样算法
对于一各给定的词,如何生成NEG(w)?
词典D中的词在语料C中出现的次数有高有低,对于那些高频词,被选为负样本的概率比较大,反之对于那些低频词,被选中的概率就比较小。这就是对采样过程的大致要求,本质上就是一个带权采样问题。
具体做法是,建立一个等距划分到不等距划分的映射,然后再随机的抽取等距划分的数字,再查表取出不等距的数字即可。
为什么要使用Hierarchical Softmax或Negative Sampling
前面提到的skip-gram中的条件概率,实际是一个多分类的logostic regression,即softmax模型。普通的方法是对条件概率的分母–要对所有词汇表里面的单词进行求和,使得计算梯度十分耗时。
Hierarchical sofmax借助了分类的概念,把词按照类别进行分类。对于二叉树来说是使用二分类近似原来的多分类。虽然在论文中作者是用哈夫曼编码构造的一连串二分类,但是训练过程,模型会赋予这些抽象的中间节点一个合适的向量,这个向量表示了他对应的所有子节点。因为真正的单词共用了这些抽象的子节点的向量,所以Hierarchical方法和原始问题并不是等价的,但是这种近似不会显著带来性能上的损失同时又使得模型的求解规模显著上升。
Negative Sampling也是采用二分类近似多分类,区别在于使用的是Oone-vs-one的方式近似,即采样一些负例,调整模型参数使得模型可以区分正例和负例。换一个角度来看就是NegeativeSampling有点lan,不想把分母中所有词都算一次,就稍微选几个算一下,选多少就是模型中负例的个数,怎么选,就需要按照词频对应的概率分布来随机采样了。
一些细节问题
sigmod函数
在[-6,6]直接用sigmod,但是其他范围函数接近于0就直接取0,避免计算,提高效率。
词典存储
哈希技术
低频词和高频词
设置阈值,删掉出现次数小于阈值的词。高频词,subsampling。
窗口以及上下文
设置一个窗口阈值,随机取前后各c个词。
自适应学习率
预先设置一个初始值,然后处理完一定数目后,根据已经处理过的数量来调整学习率。
word2vec高效的原因
- 去掉了费时的非线性隐层
- 哈夫曼树相当于做了一定的聚类,不需要统计所有的词对
- Negative Sampling
- 随机梯度下降
- 只过一遍数据不需要反复迭代
