JVM学习(1)--Java虚拟机的运行机制
来源:
https://yq.aliyun.com/articles/49201?spm=5176.100240.searchblog.69.vchDL7
http://www.cnblogs.com/kubixuesheng/p/5199200.html
Java的两大基石:Java语言规范和JVM规范
- Java语言规范:规定了语法、变量、类型、文法。Java余元规范定义了什么是java语言
- JVM规范:规范了Class问价类型、运行时数据、帧栈、虚拟机的启动、虚拟机的指令集,JVM规范。主要定义二进制class文件和JVM指令集等,且要明确的问题是Java语言与JVM相对独立,不论何种语言,单反符合了JVM规范,都可以在JVM上运行,比如Groovy,Clojure,Scala
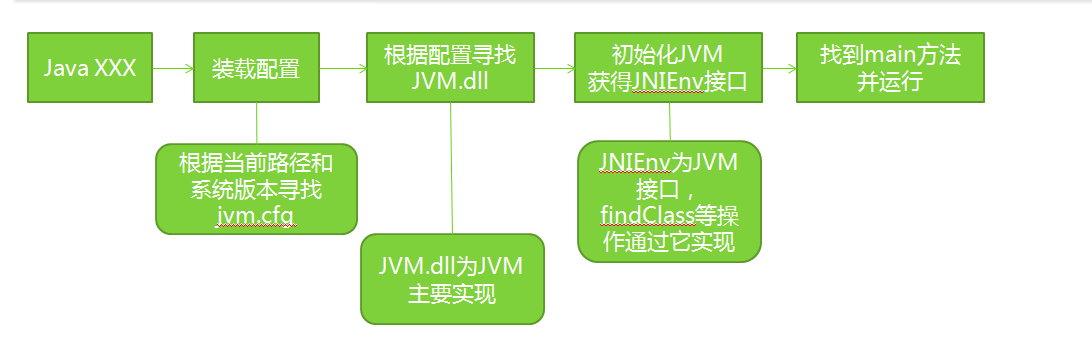
JVM的启动过程
也就是JVM如何一步步找到main方法的
- 首先使用JAVA命令启动虚拟机
- 其次进行JVM配置的装载–根据当前路径和系统的版本寻找jvm.cfg文件,装载配置
- 通过该文件去初始化JVM,并获得相应接口,比如JNIEnv接口,通过该接口实现findClass操作
- 最后,通过相关接口(JNIEnv…),找到程序里的main方法,即可进入程序
介绍一下JVM的基本结构,并说出各个模块的功能
结合这个经典的图做个解释:
首先,JVM有一个类加载系统(不然类没法执行),也就是ClassLoader。class文件(Java编译之后的)通过类加载器加载到JVM中,而JVM的内存空间是分区的,主要分为以下几个区:
- 方法区
- Java堆
- Java栈
- 本地方法栈(也就是native方法调用)
类比物理CPU,JVM也需要一个指令来指向下一条指令的地址,就是图中的PC寄存器,接着是执行引擎,用来执行字节代码,当然还有一个重要的模块–GC(垃圾回收器)。下面单租总结各个模块: - PC寄存器
java程序里的每个线程都拥有一个PC寄存器,线程私有的,每当线程启动PC寄存器时候就创建了,它是一个指针,总是用来指向下一跳指令的地址,让程序知道下一步需要做啥,且执行本地方法的时候,PC的值为undefined(未定义) - 方法区
保存JVM加载的类的信息,比如类型的常量池、类中的字段、类中的方法信息、方法的字节码(bytecode)等。但是这不是绝对的,比如JDK 6,String等字符串常量的信息是至于方法区中,JDK 7的时候已经移动到了Java堆,所以方法区也好,Java堆也罢,到底保存了什么没有具体定论,要结合不同的JVM版本进行分析,因为技术是发展的。一般认为,方法区就是保存了JVM加载的类的信息。通常方法区和永久取关联在一起,用就去是JVM里常见概念,保存了相对来说比较稳定的数据。 - Java堆
java堆是和程序开发紧密相关的一块内存区间,可以说,应用系统的对象都保存在Java堆中,且所有的线程共享Java堆,也就是说Java堆是全局共享的;从GC角度看,对使用了分带算法的GC来说,必须堆也是对应分代的,因为Java堆是GC的主要工作区间。比如下图,分代的堆:

首先有个eden代–是对象出生的地方,还有s0,s1使用复制算法。最后还有一个老年代tenured–年龄比较大的对象。 - Java栈
java栈和java堆是完全不一样的,上面说的java堆是全局共享的(all线程访问),而java栈是线程私有的,java栈由一系列的帧组成(因此java栈也叫作帧栈),栈众所周知是先进后出的结构,java栈也不例外。java栈中每个帧都保存一个方法调用的局部变量、操作数栈、指向常量池的指针等,且每一次方法调用都会创建一个帧,并压栈。
java栈里的局部变量表
该表不仅仅只是方法里的局部变量,而是更加宽泛的包含了方法的参数以及局部变量,放方法调用的时候,会在java栈里创建一个帧,帧里的局部变量表保存了方法的参数和局部变量。如下面一个静态方法:
|
|
编译之后的具备变量表字节码如下:
|
|
可以认为java栈帧里的局部变量又很多槽位组成,每个槽最大可以容纳32位的数据类型,故方法参数里的int i参数占据了一个槽位,而long l占据了两个槽 1和2,Object 对象类型其实只是一个引用,O相当于一个指针,32位。byte类型升为int(?)也是32位。
再看看实例方法:
编译之后的:
|
|
实例方法的局部变量表和静态方法基本一样,唯一区别就是实例方法在Java栈帧的局部变量表里第一个槽位(0位置)存的是一个this引用(当前对象的引用),后面就和静态方法的一样了。
如上一个递归调用(栈的内存溢出),当类中方法(静态 or 实例)调用的时候,就会在Java栈里创建一个帧,每一次调用都会产生一个帧,并持续的压入栈顶……一直到Java栈满了,就发生了溢出!或者方法调用结束了,那么对应的Java栈帧就被移除。
注意,一个Java栈帧里除了保存局部变量表外,还会保存操作数栈,返回地址等信息。顺势我在分析下Java栈帧里的操作数栈,理解Java栈帧里的操作数栈前先知道一个结论——因为Java没有寄存器(PC寄存器?),故所有参数传递使用Java栈帧里的操作数栈。
对JVM对内存进行配置可以使用哪个命令参数
-Xms 10m,表示JVM Heap(堆内存)最小尺寸10MB,最开始只有 -Xms 的参数,表示 “初始” memory size(m表示memory,s表示size),属于初始分配10m,-Xms表示的“初始”内存也有一个“最小”内存的概念(其实常用的做法中初始内存采用的也就是最小内存)。
-Xmx 10m,表示JVM Heap(堆内存)最大允许的尺寸10MB,按需分配。如果 -Xmx 不指定或者指定偏小,也许出现java.lang.OutOfMemory错误,此错误来自JVM不是Throwable的,无法用try…catch捕捉。
java的server模式和client模式的区别?
- client,server两个参数可以设置JVM使用何种运行模型,client模式启动较快,但是运行性能和内存管理效率不如server模式,常用于客户端程序;相反sever模式启动比client慢,但是可以获得更高的运行性能,常用于服务器程序。
- windows上,缺省的虚拟机类型为client模式(java –version查看)(我的是server?Java HotSpot(TM) 64-Bit Server VM (build 25.77-b03, mixed mode))如果要使用server模式,需要在启动虚拟机时候加-server参数,以获得更高性能;对服务器端应用,推荐server模式,尤其是多个cpu的系统。
- Linux上缺省使用server模式。
- 官方这样介绍:JVM Server模式与client模式启动,最主要的差别在于:-Server模式启动时,速度较慢,但是一旦运行起来后,性能将会有很大的提升。JVM工作在Server模式可以大大提高性能,但应用的启动会比client模式慢大概10%。当该参数不指定时,虚拟机启动检测主机是否为服务器,如果是,则以Server模式启动,否则以client模式启动,Java 5.0检测的根据是至少2个CPU和最低2GB内存。
综上,当JVM用于启动GUI界面的交互应用时适合于使用client模式,当JVM用于运行服务器后台程序时建议用Server模式。
JVM在client模式默认-Xms是1M,-Xmx是64M;
JVM在Server模式默认-Xms是128M,-Xmx是1024M。可以通过运行:java -version来查看jvm默认工作在什么模式。
什么是JVM逃逸分析(Escape Analysis)
所谓逃逸分析,是JVM的一种内存分配的优化方式,一些参考书这样写到:在编程语言的编译优化原理中,分析指针动态范围的方法称为陶艺分析。通俗一点将,就是当一个指针对象被多个方法或者线程引用的时候,我们称这个指针发生了逃逸。而用来分析这种逃逸现象的方法就称之为逃逸分析。
(待学习再补充)
我们知道java对象是在堆里分配的,在Java栈帧中,只保存了对象的指针。当对象不再使用后,需要依靠GC来遍历引用树并回收内存,如果对象数量较多,将给GC带来较大压力,也间接影响了应用的性能。减少临时对象在堆内分配的数量,无疑是最有效的优化方法,接下来,举一个场景来阐述。
假设在方法体内,声明了一个局部变量,且该变量在方法执行生命周期内未发生逃逸(在方法体内,未将引用暴露给外面)。按照JVM内存分配机制,首先会在堆里创建变量类的实例,然后将返回的对象指针压入调用栈,继续执行。这是优化前,JVM的处理方式。
逃逸分析优化 – 栈上分配,优化原理:JVM分析找到未逃逸的变量(在方法体内,未将引用暴露给外面),将变量类的实例化内存直接在栈里分配(无需进入堆),分配完成后,继续在调用栈内执行,最后线程结束,栈空间被回收,局部变量也被回收。这是优化后的处理方式,对比可以看出,主要区别在栈空间直接作为临时对象的存储介质。从而减少了临时对象在堆内的分配数量。
JVM栈、堆和方法区的交互
下面是一个JVM内存结构图: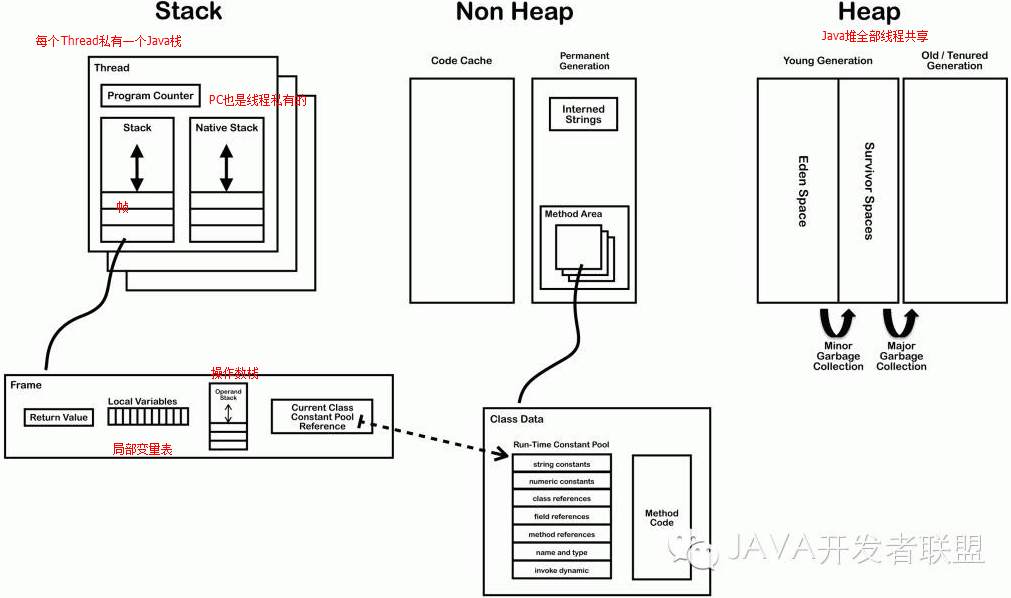
举例说明三者之间的交互原理:
众所周知,通常Java程序都要从main方法进入,故一般情况下Java程序都有一个main方法,而它本身也是一个线程(主线程),自然就对应一个Java栈,main方法也就对应一个Java的栈帧了。而根据之前JVM结构的分析,我们知道类会被JVM装载,那么JVM装载的类的信息放在了方法区里(包括字段信息,方法本身的字节码等,当然main方法也不例外),而方法体内的局部变量(包括形参),本例是对象的引用,统一放到Java栈帧里。而对象本身存放到了Java堆。如下注释:
画成图就是这样:类中方法本身(字节码)存放在方法区,Java栈里的对象引用指向了Java堆里的对象,之后堆里的对象需要的类的信息要去方法区里(非堆区)读取。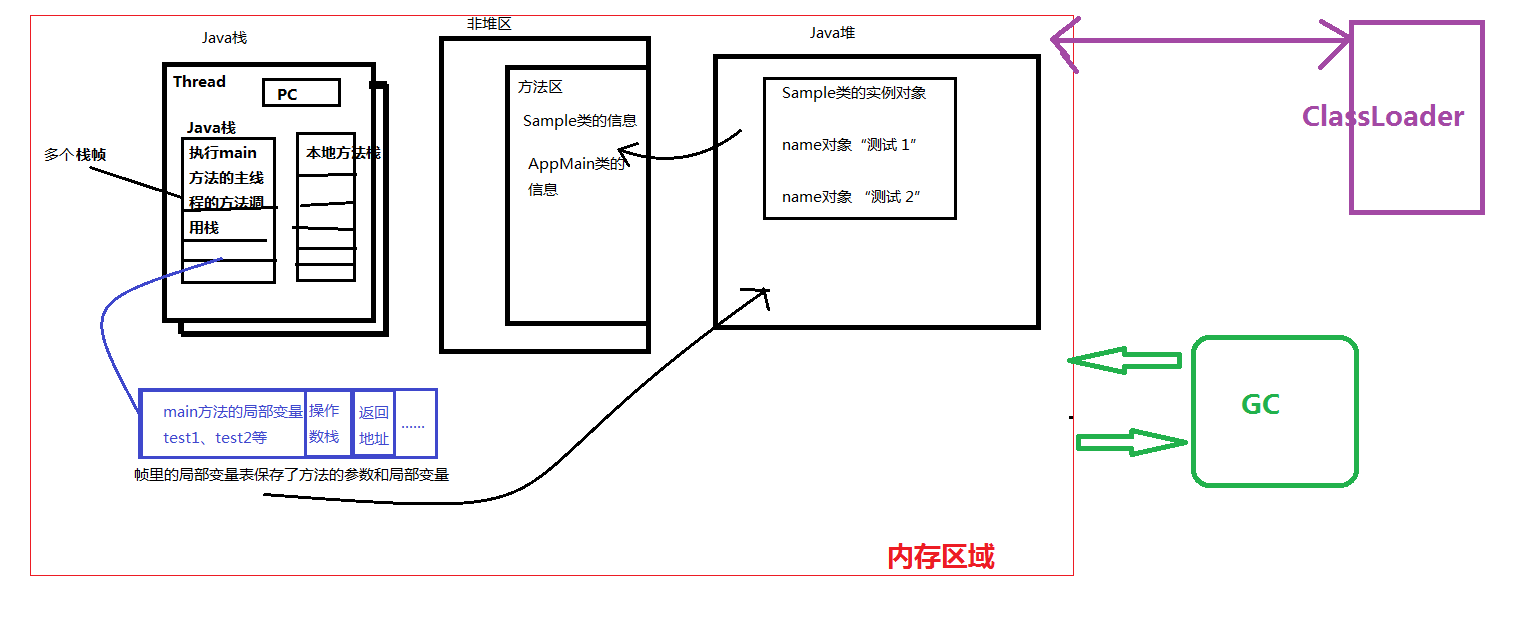
为了能让递归方法调用的次数多一些,应该怎么做?
因为传统的递归都是在栈上根据调用顺序依次申请内存空间(栈帧)进行运算,然后层层回调,这是基于上一层运算依赖于下一层的运算结果(或者说上一层的运算还没做完,需要下一层返回的结果)。
后来人们发现,对于该递归而言,一些压栈操作并无必要,递归中的子问题规模几乎不变,每次只减去了1或者2。如果画一个递归树,会发现很多相同的子树!!!说明该实现浪费了很多内存和时间。
- 优化1:使用自底向上的算法–线性递归。线性递归每次调用时,针对上一次调用的结果,它不进行收集(保存),只能依靠顺次的展开,这样也很消耗内存。
- 优化2:尾递归,它比线性递归多一个参数,这个参数是上一次调用函数得到的结果,尾递归每次调用都在收集结果,避免了线性递归不收集结果只能依次展开,消耗内存的坏处。尾递归的情况是下层计算结果对上层“无用”(上一层运算已经做完,不依赖后续的递归),为了效率,直接将下一层需要的空间覆盖在上一层上,尾递归和一般的递归不同在对内存的占用,普通递归创建stack累积而后计算收缩,尾递归只会占用恒量的内存(和迭代一样)。通俗的说,尾递归是把变化的参数传递给递归函数的变量了。
怎么写尾递归?形式上只要最后一个return语句是单纯函数就可以。如return tailrec(x+1); 而不是return tailrec(x+1) + x;
更形象的解释(来自网络):
普通递归
function story() {
从前有座山,山上有座庙,庙里有个老和尚,一天老和尚对小和尚讲故事:story(),小和尚听了,找了块豆腐撞死了 // 非尾递归,下一个函数结束以后此函数还有后续,所以必须保存本身的环境以供处理返回值。
}
尾递归:
function story() {
从前有座山,山上有座庙,庙里有个老和尚,一天老和尚对小和尚讲故事:story() // 尾递归,进入下一个函数不再需要上一个函数的环境了,得出结果以后直接返回。
}
综上,可以尽可能高效的利用栈空间,增加递归调研数。
